In de volgende paragrafen gaan we verder in op onze ervaringen met LENA en bespreken we de voor- en nadelen van LENA, en de mogelijke toepassing van LENA in de praktijk.
Ervaringen uit onderzoek
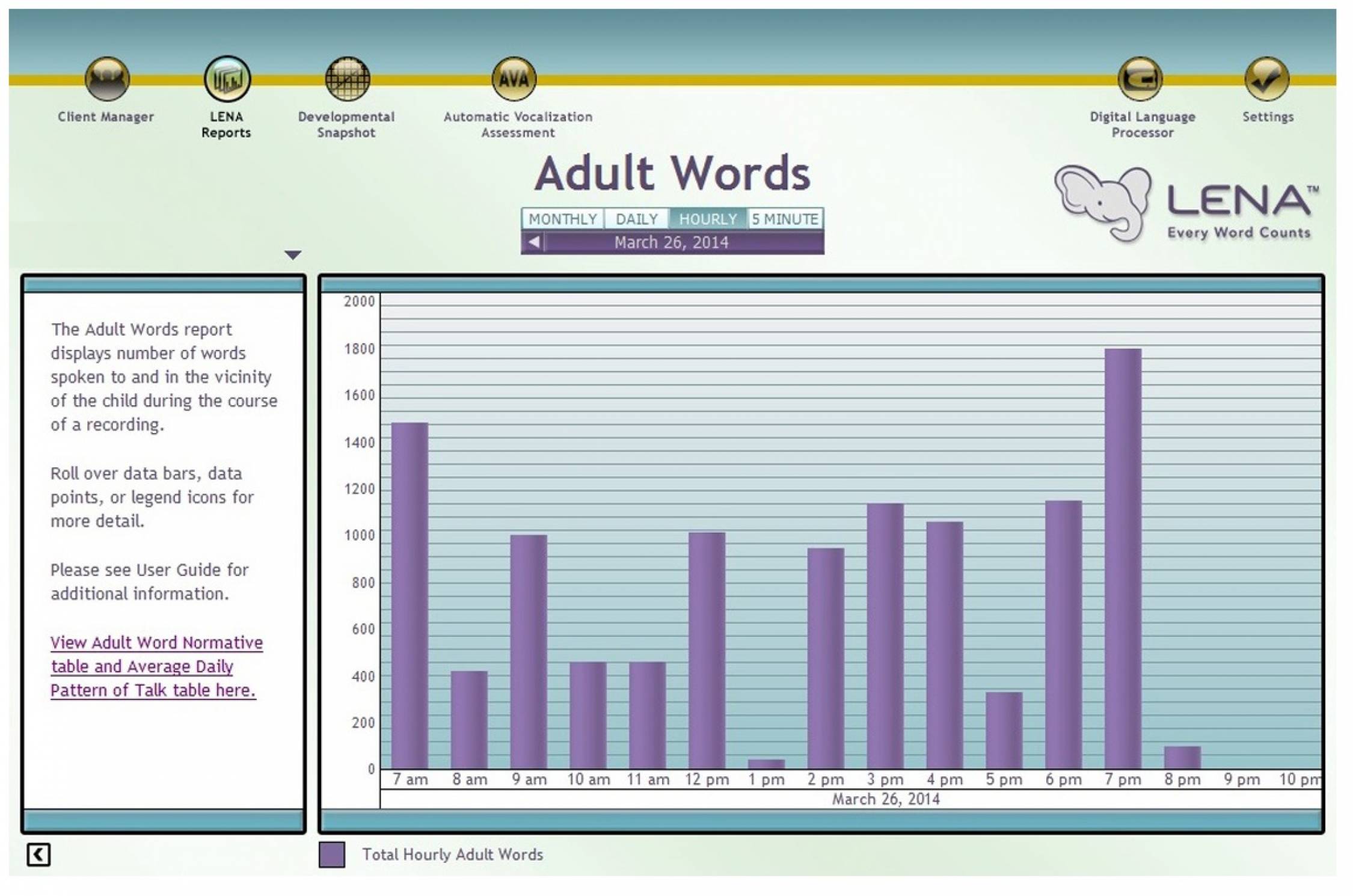
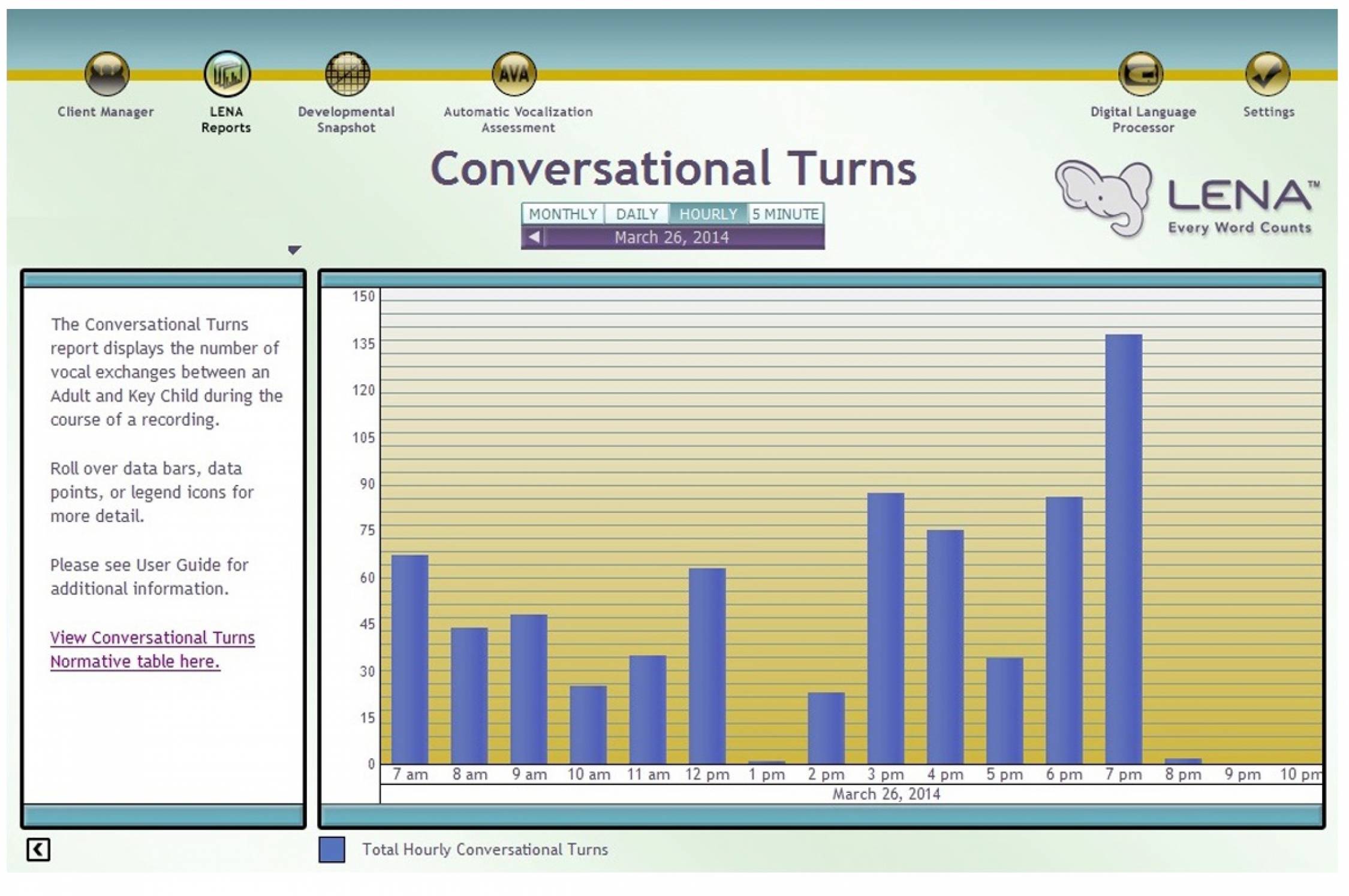
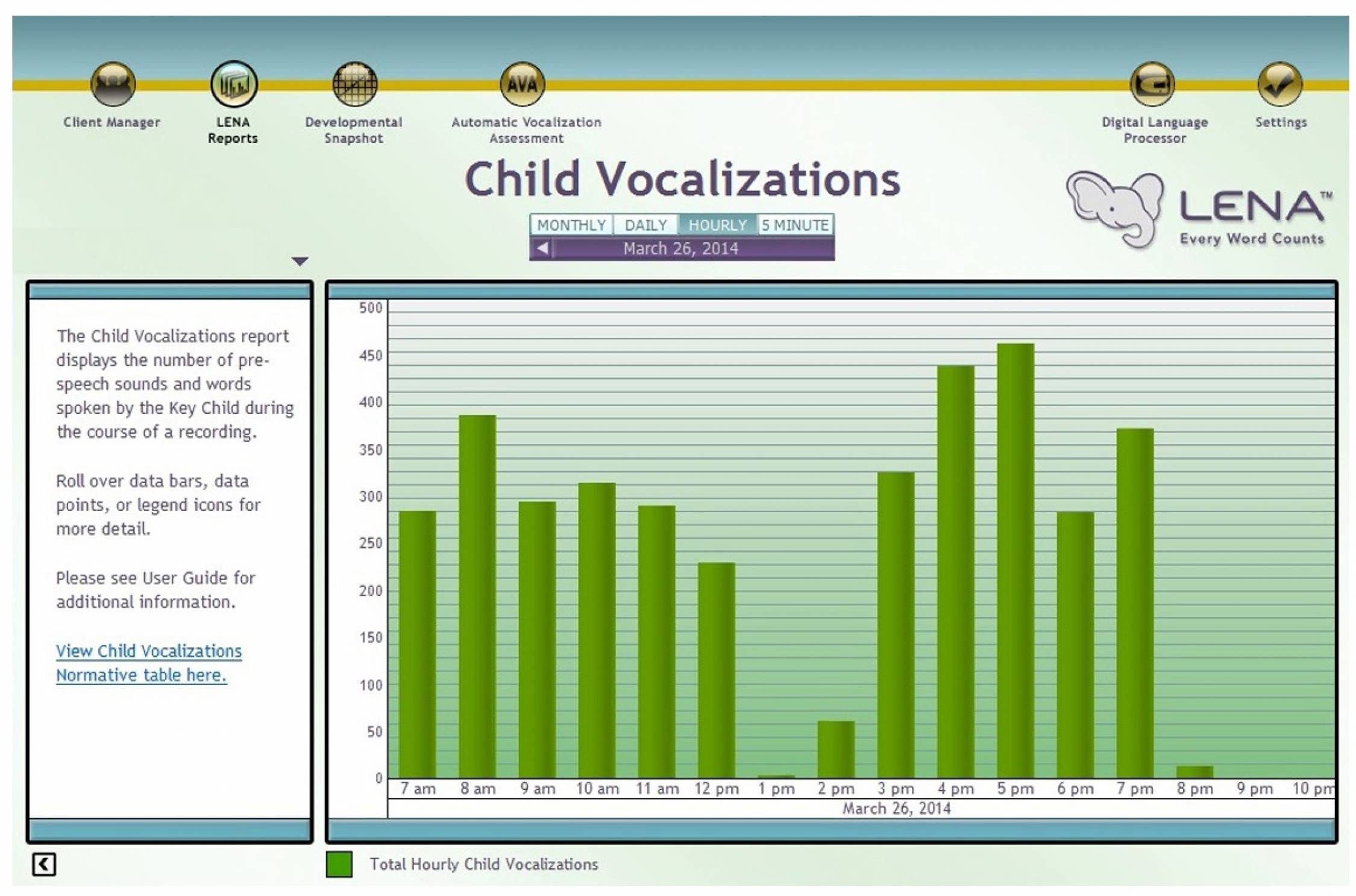
De kracht van LENA ligt in een snelle automatische analyse van langdurige spraakopnames op basis van een set vaste variabelen. De grafieken die de LENA software geeft zijn duidelijk en bieden de mogelijkheid om per dag, per uur of per 5 minuten de verschillende variabelen te bekijken en de fragmenten af te luisteren. Ook kunnen de taalvariabelen (adult word count, child vocalisations, conversational turns) vergeleken worden met normgegevens van Amerikaanse leeftijdsgenootjes. Een kanttekening is dat deze normgegevens gebaseerd zijn op Amerikaanse kinderen.
LENA BIEDT is de mogelijkheid om vanuit de grafieken naar wens fragmenten terug te luisteren
LENA wordt thuis gedurende de hele dag door de kinderen gedragen. Op die manier vinden de spraakopnames plaats in een natuurlijke setting en vindt er geen selectie plaats van wat er opgenomen en geanalyseerd wordt. Tegelijkertijd kan LENA een inbreuk zijn op de privacy, omdat LENA letterlijk de woonkamer binnenkomt. Om de privacy van de deelnemende gezinnen te waarborgen konden ouders in een speciaal dagboekje aankruisen of er gedurende dag activiteiten of gesprekken waren die verder niet meegenomen mochten in het onderzoek. Van deze optie is door geen van de ouders gebruik gemaakt. Deelnemende ouders gaven bovendien aan dat ze zich na verloop van tijd niet meer bewust waren dat hun kind LENA bij zich droeg.
Dat LENA opnames maakt in een natuurlijke setting en automatisch analyseert heeft ook een keerzijde; in een natuurlijke setting is naast spraak bijna altijd ook ander geluid, denk aan een huilende baby of een voorbijrijdende auto. Daarnaast is er in een natuurlijke setting vaak sprake van meerdere sprekers die door elkaar heen praten. LENA probeert dit op te lossen door alleen spraakopnames die boven een bepaald aantal decibel zitten, of spraak die niet overlapt, mee te nemen in de analyses. LENA doet hiermee de aanname dat zachte of overlappende spraak niet verstaanbaar is voor het kind. Uit onze ervaring van het terugluisteren van fragmenten bleek dat wij een deel van deze spraak wel kunnen verstaan en het kind dus waarschijnlijk ook. Hiermee mist LENA in de analyses mogelijk een deel van het taalaanbod. Bovenstaande betekent dat de Adult Word Count die LENA geeft een onderschatting is van het werkelijk aantal woorden dat het kind gehoord heeft.
Daarnaast maakt LENA soms fouten in het identificeren van sprekers. LENA kan een volwassen vrouw met een hoge stem bijvoorbeeld foutief identificeren als het kind, of omgekeerd. LENA heeft nou eenmaal geen mensenoren en worden er in geautomatiseerde analyse onvermijdelijk fouten gemaakt. Het is van belang dat de gebruikers van LENA zich bewust zijn van deze fouten en waarborgen dat de opnames die met LENA gemaakt worden lang genoeg zijn (minimaal 10 uur) om de foutenmarge te beperken.
Een ander aandachtspunt voor de interpretatie van de Adult Word Count is dat LENA geen woorden of woordgrenzen herkent en dus ook niet letterlijk woorden kan tellen, maar een schatting maakt. Deze schatting is een uitkomst van een algoritme dat gebaseerd is op de structuur en duur (gemiddeld aantal consonanten en vocalen) van Amerikaanse woorden. De vraag is in hoeverre dit algoritme een goede schatting geeft voor het Nederlands. Dit hebben we getest door van verschillende gezinnen de woorden binnen een aantal geluidsfragmenten handmatig te tellen. Hiervoor hebben we alleen fragmenten gebruikt die LENA heeft gelabeld als verstaanbaar voor het kind (overeenkomend met “dichtbij & geen overlap” in Figuur 2). Uit de uitkomsten blijkt dat LENA meer woorden telt dat er handmatig geteld zijn; de verhouding tussen LENA en de handmatige tellingen is gemiddeld 118%. Dit betekent dat als beoordelaars 100 woorden tellen, LENA er 118 telt. Het (op het Amerikaans) gebaseerde algoritme dat LENA gebruikt geeft dus een overschatting van het aantal woorden voor het Nederlands. Dit verschil zou verklaard kunnen worden door het feit dat Nederlandse woorden gemiddeld langer zijn dan Engelstalige woorden.
Uit bovenstaande blijkt dat LENA een instrument is dat automatisch analyses doet en daarmee dus fouten maakt. Hierdoor kunnen de absolute aantallen die LENA geeft (bijvoorbeeld aantal beurtwisselingen) afwijken van de werkelijkheid. Ondanks deze foutenmarge is het mogelijk met LENA waardevol onderzoek te doen door vergelijkingen tussen groepen te maken of veranderingen in de tijd te meten. LENA kan in de toekomst bijvoorbeeld ingezet worden om te kijken in welke mate een interventie de taalinput van de ouder naar het kind toe vergroot. Omdat LENA kwantitatieve variabelen geeft zou het voor onderzoeksdoeleinden ook interessant zijn om binnen gezinnen de hoeveelheid taalinput voor, tijdens en na een interventie in kaart te brengen.
Toepassingsmogelijkheden voor de praktijk
LENA is geschikt voor het doen van onderzoek, maar kan ook bij de behandeling ingezet worden. De grafieken die LENA na de opname genereert, geven op een snelle en duidelijke manier inzicht in de taalomgeving van het kind. Het beperking van LENA ten opzichte van video-opnames is wel dat het alleen inzicht geeft in de auditieve input, en dat de visuele informatie (gebaren, gezichtsuitingen, kijkrichting etc.) niet wordt meegenomen.
LENA zou voor professionals een interessante tool zijn voor gerichte oudercoaching
Daarnaast is het belangrijk dat gebruikers weten dat LENA alleen informatie over de kwantiteit van de auditieve taalinput geeft. De automatische analyses die LENA doet zeggen niets over inhoudelijke aspecten of de kwaliteit van wat er wordt gezegd. Daarbij kan LENA geen onderscheid maken tussen spraak gericht aan het kind zelf en andere spraak gedurende de dag. LENA maakt alleen onderscheid tussen taalinput die dichtbij en potentieel verstaanbaar was voor het kind en taalinput die te ver weg was of overlapte met andere spraak of geluid. LENA weet dus niet welk deel van de taalinput dichtbij het kind ook daadwerkelijk aan het kind gericht was.
Een krachtig aspect van LENA is dat het de mogelijkheid biedt om vanuit de grafieken naar wens fragmenten terug te luisteren. Op deze manier denken wij dat LENA in de toekomst goed ingezet kan worden om in te zoomen op de kwaliteit van de taalinput. De kwantitatieve variabelen die LENA geeft kunnen bijvoorbeeld gebruikt worden om fragmenten te selecteren waarin er veel beurtwisselingen zijn. Vervolgens kunnen deze fragmenten door een behandelaar beluisterd worden om meer zicht te krijgen op de kwaliteit van de taalinput. Gedurende de periode dat een kind in Vroegbehandeling is kan er meerdere keren een LENA opname plaatsvinden, zodat het taalaanbod bij het kind thuis over langere tijd gevolgd kan worden. Desgewenst kan een professional ouder uitnodigen om gezamenlijk fragmenten terug te luisteren, en bijvoorbeeld te kijken op welke momenten van de dag de meeste beurtwisselingen zijn (en op welke momenten nog niet, om zo mogelijkheden voor uitbreiding te ontdekken). LENA zou voor professionals dus een interessante tool zijn voor gerichte oudercoaching.
Het voordeel van een LENA is dat het verkrijgen van een hele dag aan spontane spraakopnames relatief weinig tijd kost; ouders hoeven geen aparte afspraak te maken met een hulpverlener om een interactiemoment te filmen. Bovendien is er geen professional aanwezig tijdens de opnamedag, waardoor er eerder spontane interactie ontstaat. Met het oog op de hoge licentiekosten denken we dat LENA vooral voor specifieke onderzoeks- of diagnostische vragen ingezet kan worden. Ook kan LENA gebruikt worden om in te zoomen op spontaan opgenomen interactiemomenten tussen oude kind en deze kwalitatief te analyseren.
Informatie over de auteurs
Petra van Alphen is psycholinguïst en werkzaam als senior onderzoeker bij de Kentalis Academie.
Marjolein Meester is psycholoog en werkzaam als onderzoeker bij de afdelingen Onderzoek & Ontwikkeling van de NSDSK.
Evelien Dirks is psycholoog en werkzaam als senior onderzoeker bij de afdelingen Onderzoek & Ontwikkeling van de NSDSK.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}